大模型學習全攻略 從零基礎到AI專家的系統性路線圖
引言:擁抱AI時代
隨著以ChatGPT、文心一言等為代表的大模型技術席卷全球,掌握大模型開發與應用能力已成為個人職業發展和技術創新的關鍵。本路線圖旨在為零基礎新手、在校大學生以及有志于轉型的技術開發者,提供一條清晰、系統、循序漸進的學習路徑,助你從AI小白穩步成長為AI領域的專家。
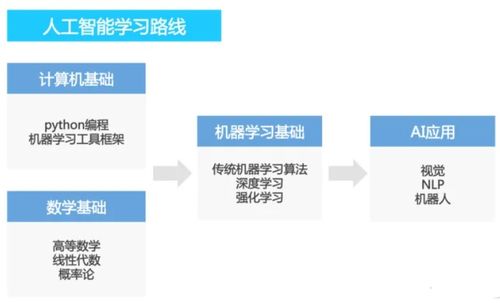
第一階段:基礎筑基(1-3個月)
目標: 構建堅實的數理與編程基礎,理解AI核心概念。
- 數學基礎:
- 線性代數: 重點掌握向量、矩陣、張量運算及其幾何意義,這是理解神經網絡數據流動的基石。
- 概率論與數理統計: 理解概率分布、貝葉斯定理、期望與方差,為學習模型的不確定性評估和生成模型打基礎。
- 微積分: 重點理解導數和梯度,這是深度學習模型訓練(反向傳播)的核心數學工具。
- 編程與工具:
- Python編程: 熟練掌握Python語法、數據結構、函數、面向對象編程及常用庫(如NumPy, Pandas)。Python是AI領域的絕對主流語言。
- 開發環境: 熟悉Jupyter Notebook、PyCharm/VSCode等IDE,學會使用Git進行版本控制和代碼托管(GitHub/Gitee)。
- 機器學習入門:
- 經典算法: 理解線性回歸、邏輯回歸、決策樹、支持向量機(SVM)等監督學習算法的原理與應用場景。
- 核心概念: 透徹理解過擬合/欠擬合、偏差與方差、交叉驗證、特征工程、模型評估指標(準確率、精確率、召回率等)。
- 推薦學習: 吳恩達《機器學習》課程(Coursera),或李航《統計學習方法》書籍。
第二階段:深度學習進階(2-4個月)
目標: 掌握深度學習的核心架構與訓練技巧,為理解大模型鋪路。
- 神經網絡基礎:
- 前向傳播與反向傳播: 深入理解神經網絡的訓練機制。
- 激活函數、損失函數與優化器: 掌握Sigmoid、ReLU、Softmax等函數,以及SGD、Adam等優化算法的原理。
- 主流網絡架構:
- 卷積神經網絡(CNN): 掌握其結構(卷積層、池化層)及其在計算機視覺(CV)中的應用(如圖像分類)。
- 循環神經網絡(RNN)與長短時記憶網絡(LSTM): 理解其處理序列數據(如文本、時間序列)的能力,是理解Transformer前的重要一步。
- 深度學習框架:
- PyTorch 或 TensorFlow: 任選其一深入學習和實踐。目前學術界和工業界(尤其在大模型領域)更傾向于PyTorch。務必動手完成從模型搭建、訓練、評估到部署的全流程項目。
第三階段:大模型核心技術(3-6個月)
目標: 深入理解大模型的基石——Transformer架構及其演進。
- Transformer架構精講:
- 核心組件: 徹底搞懂自注意力機制(Self-Attention)、多頭注意力(Multi-Head Attention)、位置編碼(Positional Encoding)、前饋網絡(FFN)的原理與實現。
- 編碼器-解碼器結構: 理解其在機器翻譯等序列到序列任務中的工作流程。
- 必讀論文: 《Attention Is All You Need》。
- 預訓練語言模型演進:
- 從BERT到GPT: 對比學習BERT(雙向編碼器,擅長理解)和GPT系列(自回歸解碼器,擅長生成)的預訓練目標(掩碼語言建模MLM vs 下一詞預測)、架構差異與應用場景。
- 大模型關鍵技術: 理解規模化(Scaling Laws)、提示工程(Prompt Engineering)、指令微調(Instruction Tuning)、基于人類反饋的強化學習(RLHF)等讓大模型“智能”涌現的關鍵技術。
- 實踐與探索:
- 使用Hugging Face: 熟練使用Hugging Face的
transformers、datasets、accelerate等庫,加載預訓練模型、進行微調、部署推理。
- 動手微調模型: 在公開數據集上,嘗試對BERT或較小的開源大模型(如ChatGLM-6B、Qwen-7B、Llama 2-7B)進行領域適配微調或指令微調。
第四階段:深入專業與前沿(持續學習)
目標: 根據興趣選擇細分方向深耕,跟蹤前沿技術。
- 專業方向選擇:
- 大模型開發與訓練: 深入研究分布式訓練、混合精度訓練、模型并行、數據并行等大規模訓練技術,了解Megatron-LM、DeepSpeed等框架。
- 大模型應用與部署: 學習模型壓縮(量化、剪枝、知識蒸餾)、服務化框架(如vLLM、TGI)、邊緣部署、AI Agent智能體構建等。
- 多模態大模型: 學習CLIP、Stable Diffusion、GPT-4V等多模態模型的原理,探索圖文生成、視覺問答等應用。
- 領域大模型: 深入金融、醫療、法律、代碼等垂直領域,研究如何利用領域數據與知識構建和優化專業模型。
- 前沿跟蹤與社區參與:
- 關注頂會與論文: 定期閱讀NeurIPS、ICLR、ACL、CVPR等頂級會議的最新論文。
- 參與開源項目: 在GitHub上閱讀優秀開源大模型項目代碼,嘗試提交Issue或PR,是快速提升的捷徑。
- 構建作品集: 通過個人博客、GitHub、技術社區分享你的學習心得、項目經驗和實驗成果,打造個人品牌。
學習建議與資源
- 保持動手: “紙上得來終覺淺,絕知此事要躬行。” 每個階段都要輔以足夠的代碼實踐和項目練習。
- 由淺入深: 不要一開始就扎進大模型論文的復雜公式,務必打好數學和深度學習基礎。
- 善用資源:
- 在線課程: 李沐《動手學深度學習》、斯坦福CS224N(NLP)、CS231N(CV)。
- 書籍: 《深度學習》(花書)、《神經網絡與深度學習》(邱錫鵬)、《自然語言處理:基于預訓練模型的方法》。
- 社區: Hugging Face、Papers With Code、知乎、AI技術博客。
##
學習大模型是一場充滿挑戰與機遇的馬拉松。這條路線圖為你規劃了清晰的階段和路徑,但最重要的是保持持續的熱情、好奇心和強大的執行力。從今天開始,邁出第一步,逐步構建你的AI知識體系與技能樹,未來已來,你正身處其中。
如若轉載,請注明出處:http://m.blmh.cn/product/44.html
更新時間:2026-04-22 23:07:18